AI自然语言处理(Natural Language Processing,NLP)是人工智能领域中人与机器通过自然语言交互的关键技术,它融合了计算机科学、人工智能和语言学,旨在让计算机理解、生成和处理人类语言。以下从核心技术、应用场景、挑战与未来趋势几个方面展开分析:
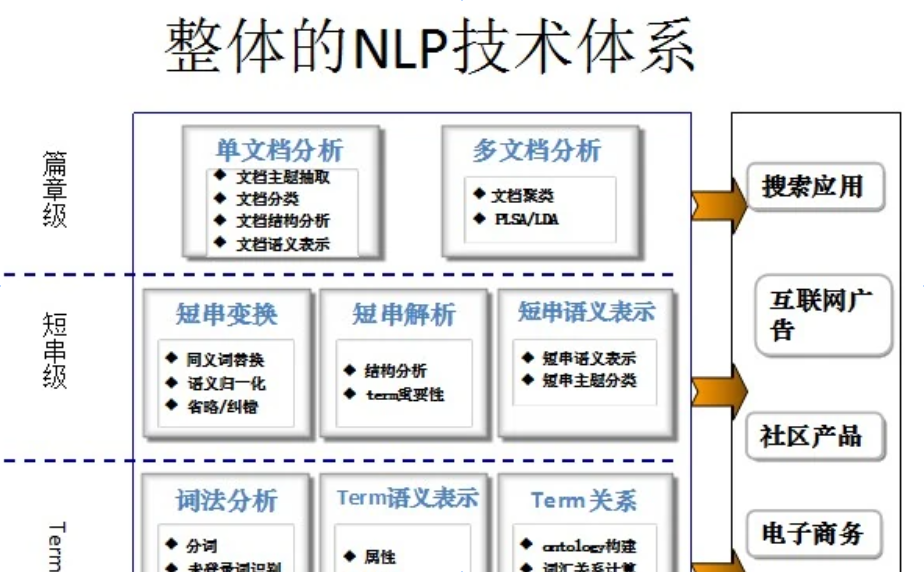
一、核心技术
词法与句法分析
- 分词与词性标注:将连续文本拆分为单词(如中文分词)并标注词性(名词、动词等),为后续处理提供基础。
- 句法分析:解析句子结构(如主谓宾关系),帮助机器理解语法规则。
语义理解
- 词义消歧:解决一词多义问题(如“苹果”指水果或公司)。
- 语义角色标注:识别句子中动作、参与者及其关系(如“小明吃了苹果”中,“小明”是施事,“苹果”是受事)。
- 知识图谱:构建实体与关系的网络(如“北京-首都-中国”),增强机器对世界知识的理解。
语言模型与生成
- 统计语言模型:基于概率预测词语序列(如N-gram模型)。
- 神经网络语言模型:利用深度学习(如RNN、LSTM、Transformer)捕捉长距离依赖关系。
- 预训练大模型:通过海量文本预训练(如BERT、GPT),再针对特定任务微调,显著提升泛化能力。
情感分析与意图识别
- 情感分析:判断文本情感倾向(正面、负面、中性),用于舆情监控或产品评价。
- 意图识别:理解用户查询的真实需求(如“附近餐厅”可能指向导航或外卖服务)。
二、应用场景
机器翻译
- 神经机器翻译(NMT):基于Transformer的模型(如Google Translate)实现多语言互译,支持实时翻译、文档翻译等。
智能客服与对话系统
- 任务型对话:处理特定任务(如订票、查询天气)。
- 闲聊型对话:模拟人类闲聊(如ChatGPT),增强用户交互体验。
语音助手
- 语音识别与合成:将语音转为文本(ASR),再通过自然语言理解(NLU)解析意图,最后生成语音回复(TTS),应用于智能音箱、车载系统等。
信息抽取与文本挖掘
- 命名实体识别(NER):从文本中提取人名、地名、组织名等实体。
- 关系抽取:识别实体间关系(如“A公司收购B公司”)。
- 事件抽取:捕捉新闻或报告中的关键事件(如地震时间、地点、震级)。
内容生成与创作
- 自动化写作:生成新闻稿、广告文案、诗歌等(如Jasper.ai)。
- 代码生成:通过自然语言描述生成代码片段(如GitHub Copilot)。
搜索与推荐系统
- 语义搜索:理解用户查询的深层意图(如“如何治疗感冒”可能关联医疗知识)。
- 个性化推荐:结合用户历史行为与文本分析,推荐商品、影视或音乐(如Netflix、淘宝)。
发表评论 取消回复